The paper proposed EfficientNet didn't aim to develop a specific network architecture but a method to scale up a certain model with taking a balance among width, depth, and resolution. However, the model architecture proposed by the authors was quite efficient and utilized in various research. This is a memo to implement EfficientNet in neural network console, a free software for deep learning produced by SONY.
- EfficientNet
- They found a optimal way to scale up the model
- Width (the number of output channels)
- Depth (the number of layers)
- Resolution (the size of input images)

[1905.11946] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (arxiv.org)
- Baseline network architecture of the EfficientNet

[1905.11946] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (arxiv.org)
- Scaling method

The actual coefficients used in this paper are as follows;[1905.11946] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (arxiv.org)
params_dict = {
(width_coefficient, depth_coefficient, resolution, dropout_rate)
'efficientnet-b0': (1.0, 1.0, 224, 0.2),
'efficientnet-b1': (1.0, 1.1, 240, 0.2),
'efficientnet-b2': (1.1, 1.2, 260, 0.3),
'efficientnet-b3': (1.2, 1.4, 300, 0.3),
'efficientnet-b4': (1.4, 1.8, 380, 0.4),
'efficientnet-b5': (1.6, 2.2, 456, 0.4),
'efficientnet-b6': (1.8, 2.6, 528, 0.5),
'efficientnet-b7': (2.0, 3.1, 600, 0.5),
'efficientnet-b8': (2.2, 3.6, 672, 0.5),
'efficientnet-l2': (4.3, 5.3, 800, 0.5),
}tpu/efficientnet_builder.py at master · tensorflow/tpu · GitHub
Substituting into the original equation from here, we get;
α = 1.2, β = 1.1, γ = 1.15,
φ = 0, 0.49, 1.07, 2.09, 3.78, 5.09, 6.14, 7.05 for b0-b7 - MBConv?
- A
MBConvis a Inverted Linear BottleNeck layer with Depth-Wise Separable Convolution.
- MBConv module structure
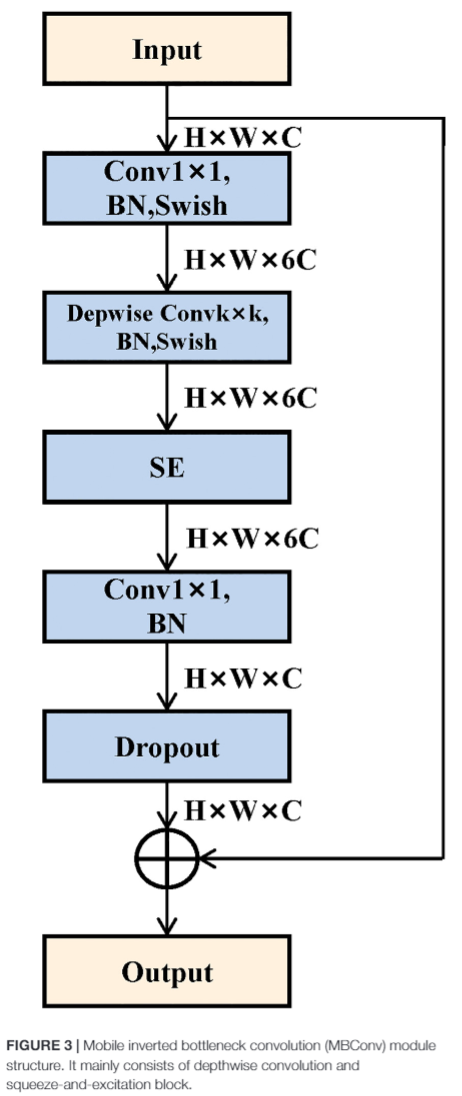
BN: batch normalization
SE: squeeze-and-excitation block
- Swish?
- A kind of activation function that has several advantages over ReLU, a common activation function for CNN.
- The choice of activation functions in deep networks has a significant effect on the training dynamics and task performance. Currently, the most successful and widely-used activation function is the Rectified Linear Unit (ReLU). Although various alternatives to ReLU have been proposed, none have managed to replace
it due to inconsistent gains. In this work, we propose a new activation function, named Swish, which is simply f(x) = x sigmoid(x).

[1710.05941v1] Swish: a Self-Gated Activation Function (arxiv.org)
- Three advantages introduced in the paper
- Avoid saturation saturation can be avoided compared to the function which is unbounded above such as tanh.
- Strong regularization effect Large negative values are output as zeros, the so-called forgetting effect, which results in a high regularization effect.
- Smoothness for model optimization and generalization
The output landscape of the Swish network is smoother, affecting the smoothness of the loss landscape and facilitating optimization.

[1710.05941v1] Swish: a Self-Gated Activation Function (arxiv.org)
- Batch normalization?
- A layer performing the normalization for each training mini-batch.
- Batch Normalization improves learning speed, suppresses overlearning, and suppresses initial value dependence.
- Batch normalization effectively increased learning efficiency.

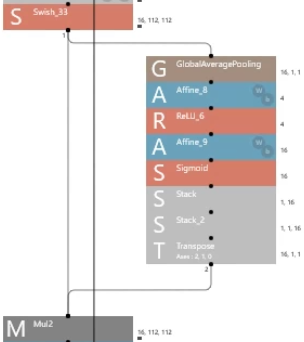
- squeeze-and-excitation block?
- Block to weight each channel of the convolution layer

- Block to weight each channel of the convolution layer
- Depthwise convolution and pointwise convolution?
- Convolution in the channel direction and in the image direction is done at the same time in the usual convolution, but by doing them separately, the computational cost can be greatly reduced.

- Convolution in the channel direction and in the image direction is done at the same time in the usual convolution, but by doing them separately, the computational cost can be greatly reduced.
- A
- They found a optimal way to scale up the model
- Other difficulties
- The smallest integer that exceeds the value calculated by multiplying the number of layers in each stage of the baseline by the depth_coefficient, where is the number of layers in each stage.
- EfficientNet-b7

- EfficientNet-b4


- EfficientNet-b7
- width (number of channels) of each block in each stage

https://towardsdatascience.com/complete-architectural-details-of-all-efficientnet-models-5fd5b736142
- stack and transpose are needed to make squeeze-and-excitation block
- The smallest integer that exceeds the value calculated by multiplying the number of layers in each stage of the baseline by the depth_coefficient, where is the number of layers in each stage.
- References
- 2019年最強の画像認識モデルEfficientNet解説 - Qiita
- EfficientNetの各モデルの係数について - Qiita
- [活性化関数]Swish関数(スウィッシュ関数)とは?:AI・機械学習の用語辞典 - @IT (itmedia.co.jp)
- Batch Normalization:ニューラルネットワークの学習を加速させる汎用的で強力な手法 - DeepAge
- 論文メモ: Squeeze-and-Excitation Networks - Qiita
- Deep Learning精度向上テクニック:様々なCNN #1 - YouTube
- Deep Learning精度向上テクニック:様々なCNN #2 - YouTube
- Depthwise Separable Convolutionについて分かりやすく解説! | AGIRobots
- MobileNet(v1,v2,v3)を簡単に解説してみた - Qiita